Hindsight 深度解析:为什么 Agent 有记忆,但还是不会学习?
- 一、Agent Memory 的困境:RAG 和 Knowledge Graph 都卡在哪
- 二、Hindsight 的解法:仿生记忆三层架构
- 三、LLM 在 Hindsight 里不是只负责"聊天"
- 四、三个核心操作:Retain、Recall、Reflect
- 五、实战:5 分钟跑起来
- 六、性能数据:SOTA 是真的,但竞争在加剧
- 七、适合谁,不适合谁
- 八、总结
- 参考文献
你的 AI 客服记住了用户上周的问题,但再次遇到类似投诉时,它还是会按标准话术回复,不会根据之前的处理结果调整策略。
这不是因为 prompt 写得不够好,而是因为大多数所谓的 "Agent Memory" 只解决了回忆,没解决学习。
Hindsight 想改变这一点。它把自己定位成 "agent memory system built to create smarter agents that learn over time" —— 不是帮你回忆对话历史,而是让 Agent 真的能随着时间变聪明。
这篇来看看它是怎么做的,以及值不值得你接入自己的项目。
一、Agent Memory 的困境:RAG 和 Knowledge Graph 都卡在哪
目前给 Agent 加记忆的常见方案就两类,但各自有天花板。
| 方案 | 原理 | 优势 | 死穴 |
|---|---|---|---|
| RAG/向量检索 | 把对话历史切片向量化,检索 top-k | 实现简单,通用性强 | 只 recall 不 learn;长上下文稀释严重;跨会话推理弱 |
| Knowledge Graph | 手动/自动抽取实体关系建图 | 结构化好,关系可追溯 | 构建成本高;维护难;对 temporal/causal 支持有限 |
RAG 的问题很直白:你把一百轮对话塞进向量库,下次检索出来的是语义相似的片段,但 Agent 不会从这段对话里总结出"这个用户喜欢直接给解决方案,不喜欢寒暄"。它只会把原始片段贴回 prompt。
Knowledge Graph 理论上能解决这个问题,但实际落地时你会发现:实体抽取质量不稳定、关系schema需要预先设计、图查询延迟高。更麻烦的是,图本身不会主动更新认知 —— 如果用户后来跳槽了,你需要额外的逻辑去处理实体冲突和信念更新。
Hindsight 的论文里有一句话很狠:
"Current generation of agent memory systems treats memory as an external layer that extracts salient snippets from conversations... they still blur the line between evidence and inference, struggle to organize information over long horizons."
翻译一下:现在的记忆系统是在给 Agent 当外挂硬盘,而不是帮它长脑子。
二、Hindsight 的解法:仿生记忆三层架构
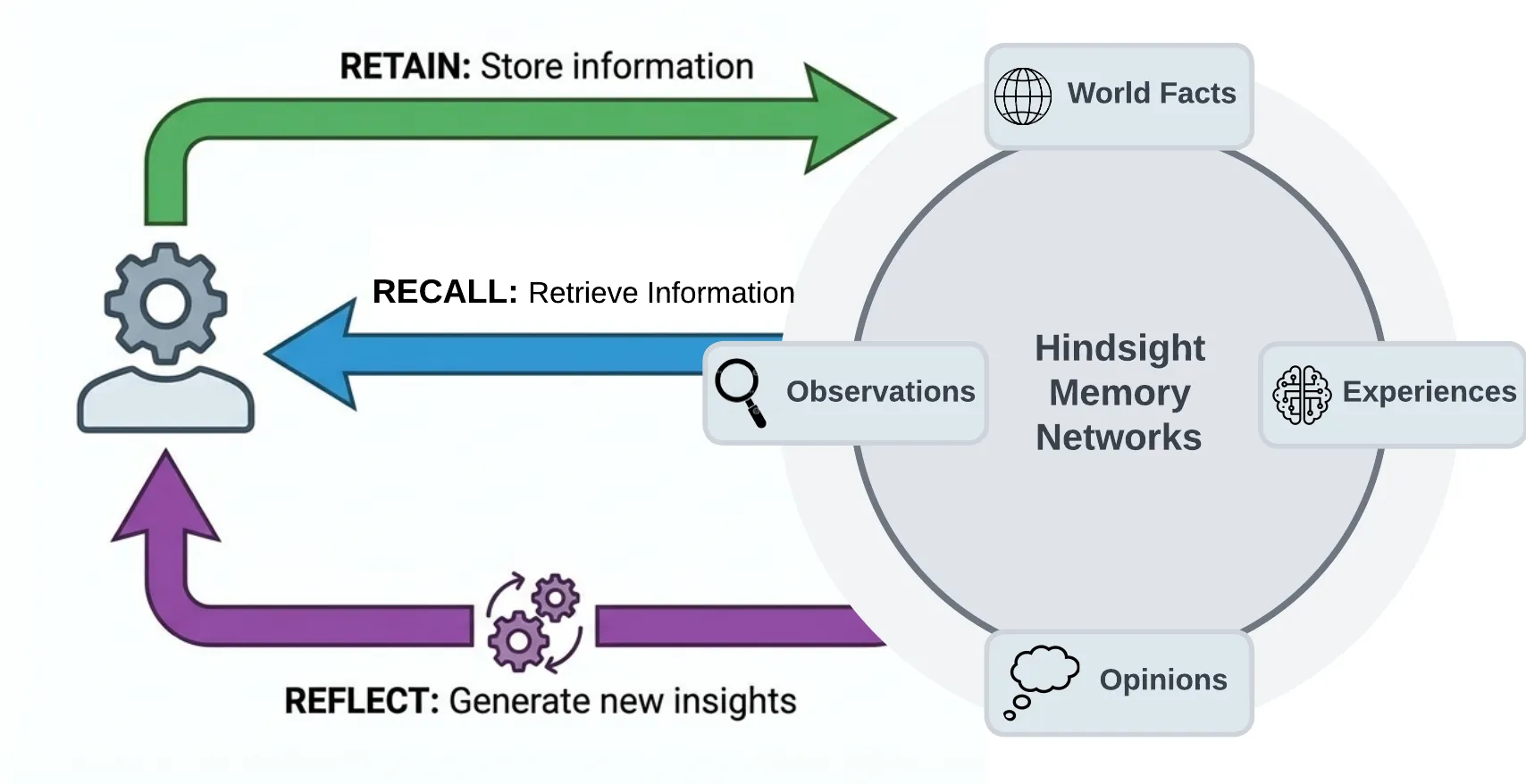
Hindsight 的核心思路是用 biomimetic data structures(仿生数据结构) 来组织记忆,模仿人类记忆的工作方式。
它把记忆分成三层:
| 层级 | 对应人类记忆 | 存储内容 | 举例 |
|---|---|---|---|
| World | 常识/事实记忆 | 关于世界的客观事实 | "火炉会烫"、"Python 是动态类型语言" |
| Experiences | 情景/ episodic 记忆 | Agent 自身的经历 | "我上周帮这个用户排查了登录问题,原因是 cookie 过期" |
| Mental Models | 抽象模型/信念 | 从经验中提炼的规律和洞察 | "这个用户遇到报错时 prefer 直接看日志,不需要解释" |
这三层不是简单的标签分类,而是有明确的流动关系:
- Experiences 流入:每次对话、每次工具调用,都是新的经历
- World 更新:从经历中提取客观事实,同步到世界模型
- Mental Models 生成:通过 Reflect 操作,从大量经历和事实中提炼出抽象认知
这和 RAG 的本质区别在哪?RAG 存储的是原始对话文本,Hindsight 存储的是结构化理解 —— entities、relationships、time series,加上 sparse/dense vector 辅助检索。原始文本只是输入原料,系统会自动完成抽取、归一化、建索引。
论文里提到他们用了四个 logical networks 来组织:world facts、agent experiences、synthesized entity summaries、evolving beliefs。后两者其实就是 Mental Models 的具体实现。
官方给的架构概览图很直观:
三、LLM 在 Hindsight 里不是只负责"聊天"
在讲三个核心操作之前,先搞清楚一件事:Hindsight 为什么需要你的 OpenAI API Key(或其他 LLM Provider 的 Key)?
普通 RAG 系统里,LLM 只干一件事——根据检索到的上下文生成回复。但 Hindsight 把 LLM 用在了记忆系统的内部流程里,LLM 在这里有三重角色:
| 角色 | 发生在哪个操作 | 具体做什么 | 为什么必须 |
|---|---|---|---|
| 信息抽取(Information Extraction) | Retain | 从原始文本提取实体(entities)、关系(relationships)、时间(temporal facts),并做归一化(normalization) | 没有这一步,记忆就无法结构化 |
| 记忆推理(Inference over Memory) | Reflect | 对已有记忆做深度分析,生成新的洞察和信念更新 | 这是"学习"的核心,不是简单检索能完成的 |
| 回复生成(Response Generation) | 最终输出 | 基于检索/推理结果生成用户可见的回复 | 和普通 Agent 一样 |
这意味着每次 retain 都会触发一次 LLM 调用。你往 Hindsight 里塞一条记忆,系统要先让 LLM 读懂、拆成结构化数据、建好索引,才存得进去。这是 Hindsight 和纯向量数据库的本质区别——向量库只管embedding,Hindsight 要 LLM 先"理解"再存。
这也解释了部署时为什么必须传 OPENAI_API_KEY(或 HINDSIGHT_API_LLM_API_KEY):没有 LLM,Hindsight 连"理解记忆"这一步都跑不通。同理,HINDSIGHT_API_LLM_PROVIDER 支持 openai、anthropic、gemini、groq、ollama、lmstudio、minimax,你可以按成本和延迟要求切换底层模型。
论文里用的是开源 20B/120B 模型做 retain 和 reflection,说明这里不一定非得上 GPT-4 级别的模型。但模型质量直接影响抽取精度和推理深度,用太弱的模型会拉低记忆质量。
四、三个核心操作:Retain、Recall、Reflect
Hindsight 的 API 设计非常克制,只有三个操作。但每个操作背后都有一整套处理逻辑。
Retain:不只是"存",而是"理解后存"
from hindsight_client import Hindsight
client = Hindsight(base_url="http://localhost:9888")
client.retain(
bank_id="my-bank",
content="Alice got promoted to senior engineer",
context="career update",
timestamp="2025-06-15T10:00:00Z"
)看起来很简单,但背后发生的事情不少:
- LLM 提取 key facts、temporal data、entities、relationships
- Normalization:把抽取结果转成 canonical entities、time series、search indexes
- 按类型分流到 World / Experiences 路径
- 更新相关 mental models
这意味着你不需要自己写实体抽取、不需要维护 schema、不需要处理冲突合并。 retain 一次,系统自己搞定后续。
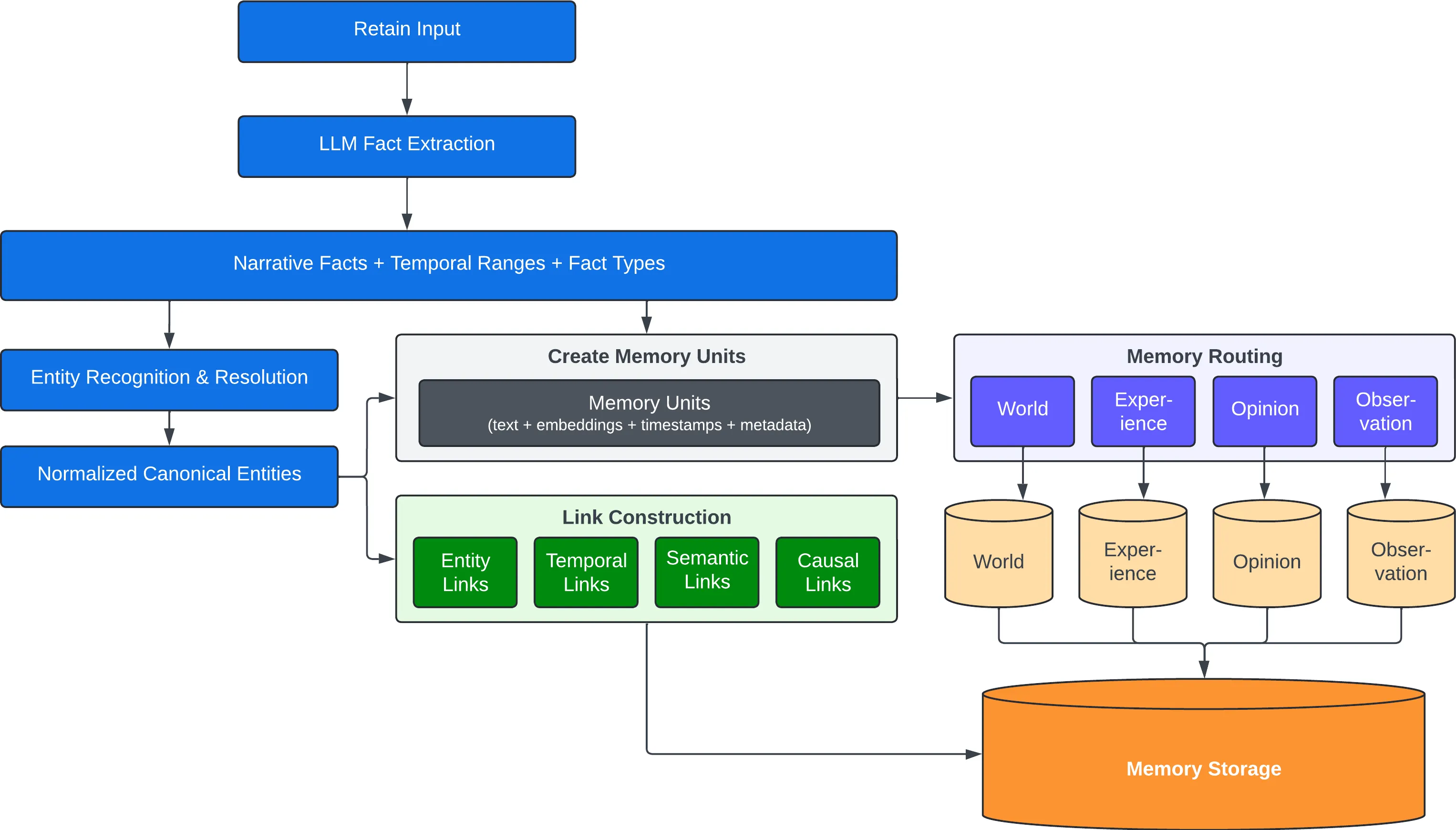
这张图展示了 retain 的完整流水线:原始文本经过 LLM 抽取,转成结构化数据后分流到 World / Experiences 路径。
Recall:四路检索 + 融合 + 重排
client.recall(bank_id="my-bank", query="What happened in June?")Recall 同时跑四种检索策略:
| 策略 | 作用 | 适用场景 |
|---|---|---|
| Semantic | 向量相似度 | 意思相近但不完全匹配 |
| Keyword | BM25 精确匹配 | 特定术语、人名、版本号 |
| Graph | 实体/时间/因果关联 | 跨实体推理 |
| Temporal | 时间范围过滤 | "上周"、"上个月"这类查询 |
四路结果用 RRF(Reciprocal Rank Fusion,倒数排名融合)合并,再用 cross-encoder reranking model(交叉编码器重排模型,比向量相似度更准但更慢)精排,最后按 token 限制截断。
这种设计明显是冲着长程记忆去的。单一向量检索在处理 "Alice 去年在哪个公司?" 这种问题时,很容易因为语义漂移而失效。四路并行+rerank 的方案在实际场景中明显更稳。
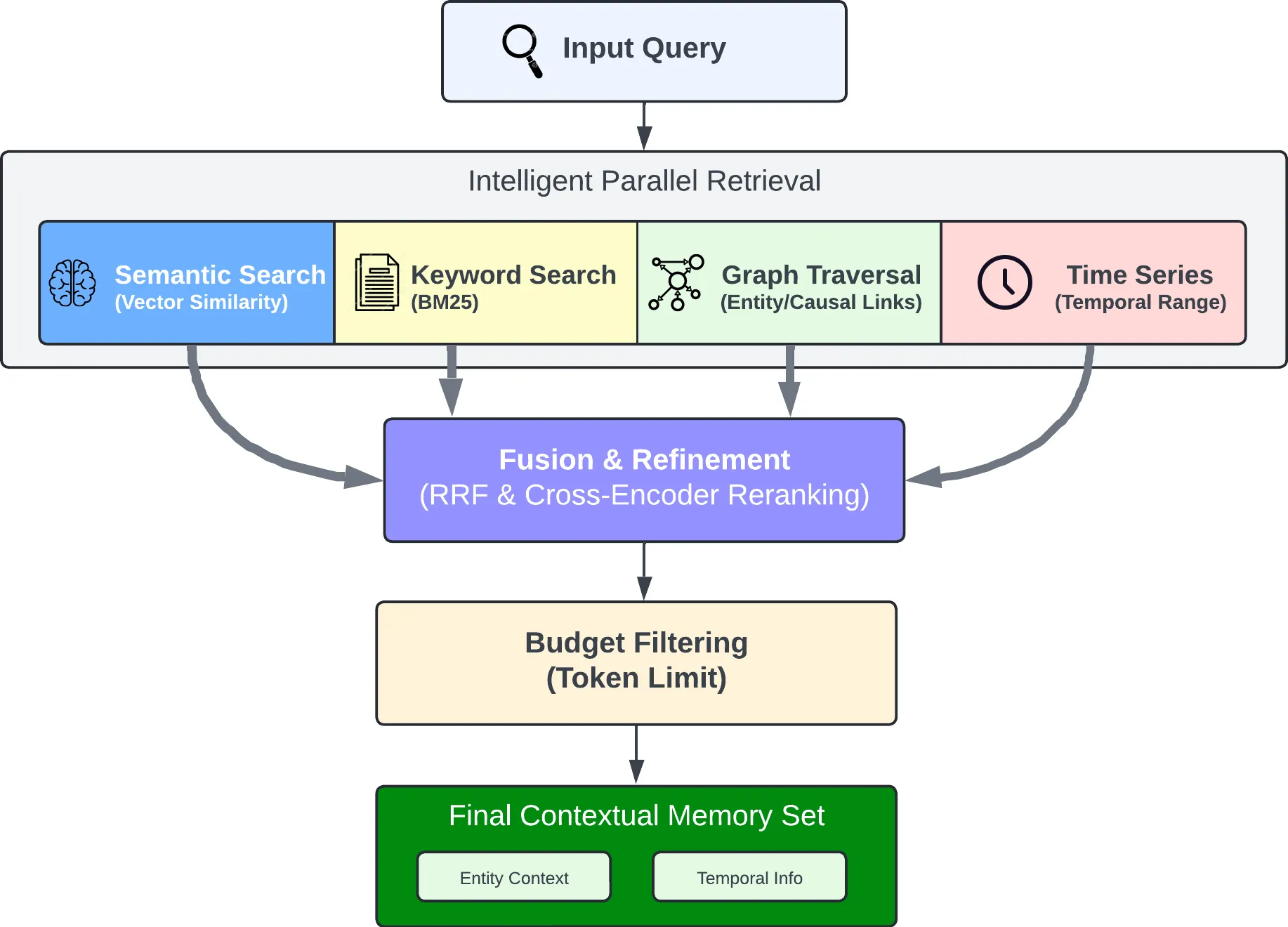
四路检索并行执行,结果经融合和精排后输出。图里能看到 Semantic、Keyword、Graph、Temporal 四条路径各自的输入和输出。
Reflect:从"回忆"到"学习"的关键
client.reflect(bank_id="my-bank", query="What should I know about Alice?")Reflect 是我认为 Hindsight 最有差异化的操作。它不是简单地检索已有记忆,而是对记忆进行深度分析,生成新的洞察。
官方给的例子很具体:
- AI Project Manager 反思项目风险
- Sales Agent 反思 outreach 效果差异
- Support Agent 反思产品文档未覆盖的客户问题
本质上,Reflect 是在做 inference over memory,而不是 retrieval from memory。它会把分散在不同会话中的事实联系起来,形成更高层的认知 —— 这正是 Mental Models 的来源。
论文里把这个能力叫做 "reflection layer reasons over this bank to produce answers and to update information in a traceable way"。traceable 这个词很重要:它意味着系统能解释"为什么我现在这么理解 Alice",而不是黑箱式地给出结论。
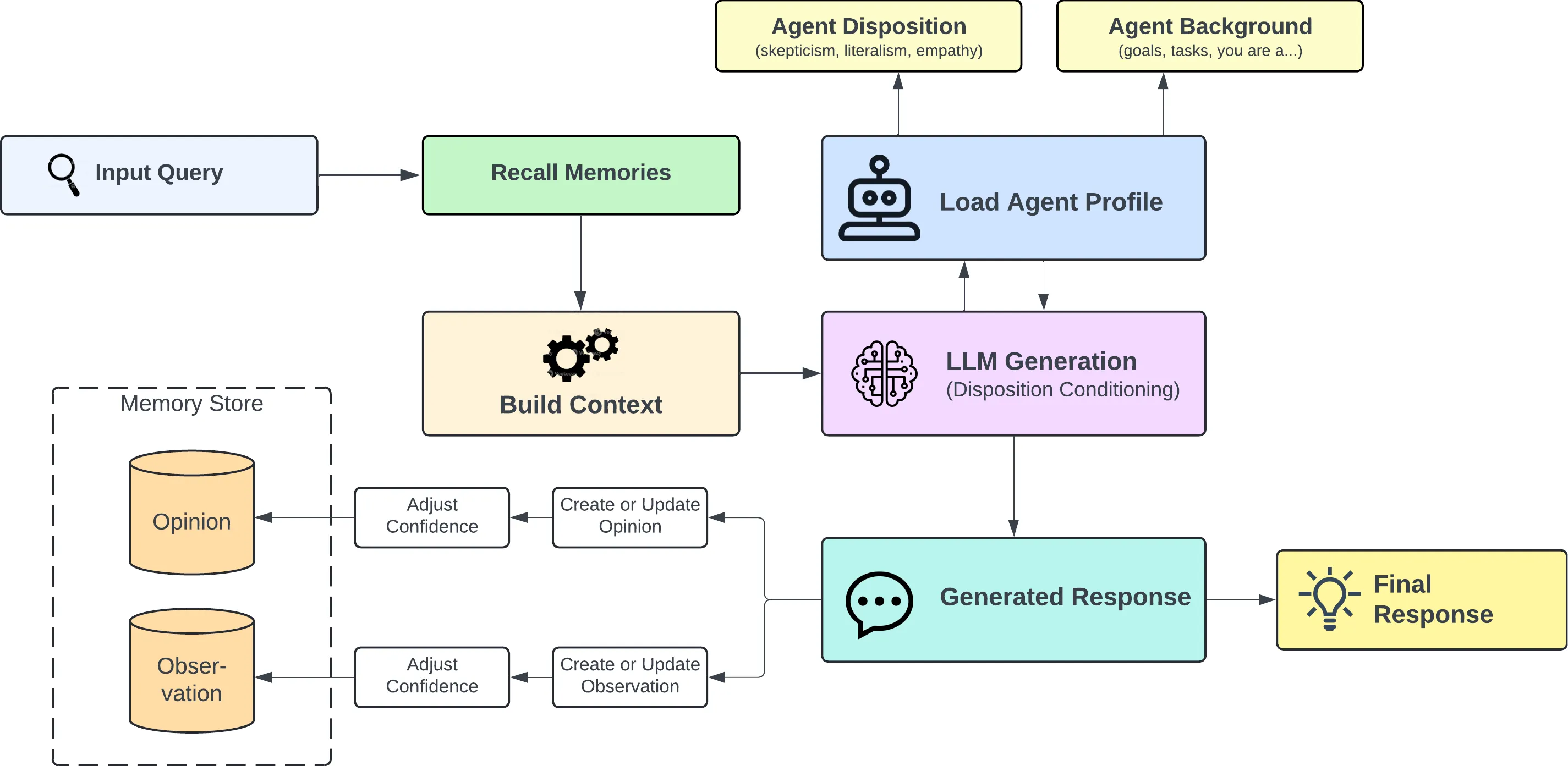
reflect 不是简单检索已有记忆,而是对记忆库做深度推理,生成新洞察并更新 Mental Models。
五、实战:5 分钟跑起来
Hindsight 的部署体验比我预期的好。最快的方式是一行 Docker:
export OPENAI_API_KEY=sk-xxx
docker run --rm -it --pull always -p 9888:8888 -p 9999:9999 \
-e HINDSIGHT_API_LLM_API_KEY=$OPENAI_API_KEY \
-v $HOME/.hindsight-docker:/home/hindsight/.pg0 \
ghcr.io/vectorize-io/hindsight:latest最好是通过 docker-compose.yml 配置,以便后续扩展。
外网访问需要开启hindsight的token校验,需要添加以下环境变量:
- HINDSIGHT_API_TENANT_EXTENSION=hindsight_api.extensions.builtin.tenant:ApiKeyTenantExtension
- HINDSIGHT_API_TENANT_API_KEY=your-secret-api-keyAPI 在 9888,UI 在 9999。内置 PostgreSQL,开箱即用。
如果你已经在用 Hermes Agent,或者有更复杂的部署需求(docker-compose、数据持久化、资源调优、踩坑排查),参考之前的实操记录:
《Hermes Memory 本地踩坑复盘:Hindsight local_external 才是稳妥路线》 — 详细讲了 docker-compose 配置、PostgreSQL 表结构、异步任务排查、资源消耗实测,以及为什么放弃 local_embedded。
纯嵌入模式(不用跑服务)
如果你只是想试试 API,不需要 Docker:
pip install hindsight-all -Uimport os
from hindsight import HindsightServer, HindsightClient
with HindsightServer(
llm_provider="openai",
llm_model="gpt-5-mini",
llm_api_key=os.environ["OPENAI_API_KEY"]
) as server:
client = HindsightClient(base_url=server.url)
client.retain(bank_id="my-bank", content="Alice works at Google")
results = client.recall(bank_id="my-bank", query="Where does Alice work?")bank_id 是记忆库的逻辑分区,不同 bank 的记忆互不可见,适合多项目共用同一个 Hindsight 实例。
SDK 支持 Python 和 Node.js,也提供 REST API 和 CLI。LLM provider 覆盖 OpenAI、Anthropic、Gemini、Groq、Ollama、LM Studio、MiniMax。
更懒的方式是用 LLM Wrapper(包装器模式——它会包一层你的 LLM client,自动在每次调用前后插入 retain/recall):
from hindsight import HindsightLLMWrapper
client = HindsightLLMWrapper(original_client)Wrapper 适合快速验证,生产环境建议直接 SDK 集成。
给 Claude Code 加记忆
如果你用 Claude Code,Hindsight 官方做了原生插件,直接 hook 到 Claude Code 的生命周期,不是间接走 MCP。
安装(两行):
claude plugin marketplace add vectorize-io/hindsight
claude plugin install hindsight-memory三种连接模式:
| 模式 | 场景 | 说明 |
|---|---|---|
| External API | 连外网/自托管 Hindsight 服务器 | 推荐用于生产。不需要本地 LLM key,服务器端处理 fact extraction |
| Local Daemon | 本地自动管理 | 插件自动启动 hindsight-embed,需要 LLM API key 做本地抽取 |
| Existing Local Server | 已有本地 Hindsight 在跑 | 留空 hindsightApiUrl,插件自动检测本地端口 |
连接外网 Hindsight 服务器的配置(~/.hindsight/claude-code.json):
{
"hindsightApiUrl": "https://f.h89.cn:9888",
"hindsightApiToken": "your-secret-api-key",
"bankId": "claude-code",
"enableKnowledgeTools": true
}hindsightApiUrl:你的 Hindsight 服务器地址hindsightApiToken:Hindsight 服务端开启 API Key 认证后生成的 TokenbankId:记忆库分区,不同 bank 的记忆互不可见enableKnowledgeTools:开启后 Claude 可以主动读写记忆(默认关闭)
初始化:创建记忆 bank
如果这是第一次使用,先创建 claude-code bank:
curl -X PUT "https://f.h89.cn:9888/v1/default/banks/claude-code" \
-H "Authorization: Bearer your-secret-api-key" \
-d '{"name":"claude-code"}'返回 200 OK 表示 bank 已创建。后续 Claude Code 插件会自动在这个 bank 里读写记忆。
启动:
claude插件自动激活。它做了两件事:
| 自动化 | 触发时机 | 效果 |
|---|---|---|
| Auto-recall | 每次你输入 prompt | 自动查询 Hindsight 相关记忆,注入 Claude 上下文(你看不到,Claude 能看到) |
| Auto-retain | 每次 Claude 回复后 | 自动提取对话内容,长期存储到 Hindsight |
昨天告诉它的代码规范、项目约定、你的偏好,今天开新 session 它还记得。这就是跨 session 长期记忆。
Knowledge Tools(需要 enableKnowledgeTools: true):
开启后 Claude 可以主动调用以下工具:
agent_knowledge_recall— 主动搜索记忆agent_knowledge_ingest— 把文本内容写入记忆agent_knowledge_create_page— 创建知识页面(Mental Models)
需要手动控制时:
- 关掉 auto-retain:
export HINDSIGHT_AUTO_RETAIN=false - 关掉 auto-recall:
export HINDSIGHT_AUTO_RECALL=false - 按项目隔离记忆(dynamic bank):
"dynamicBankId": true, "dynamicBankGranularity": ["agent", "project"]
关于 bankId:要不要和 Hermes/OpenCode 共用?
bankId 是记忆库的分区,不同 bank 的记忆互不可见。各工具的默认值不同:
| 工具 | 默认 bankId | 如果改成共用 |
|---|---|---|
| Hermes | hermes |
共享全部记忆,但博客选题和代码规范可能互相干扰 |
| Claude Code | claude_code |
独立 bank,干净但跨工具不互通 |
| OpenCode | 插件自定 | 同上 |
建议:编码工具(Claude Code / OpenCode)之间可以共用 coding bank,让代码规范和项目结构跨工具互通;但不要把写作工具(Hermes)的记忆混进来,避免 recall 时召回不相关内容。
具体配置参考 Hindsight Claude Code 文档。
六、性能数据:SOTA 是真的,但竞争在加剧
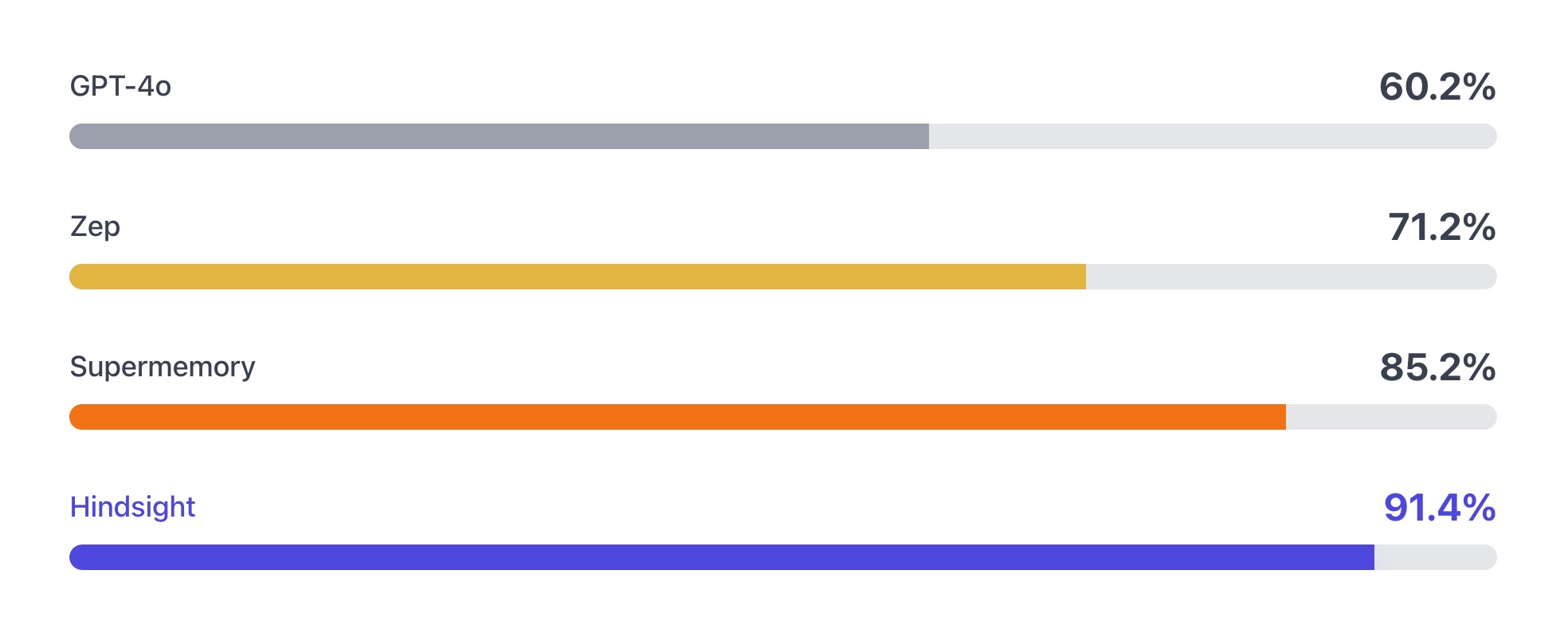
Hindsight 在 LongMemEval 和 LoCoMo 两个长程记忆 benchmark 上的数据确实亮眼:
LongMemEval(S setting,500 questions):
| 系统 | 骨干模型 | 总体准确率 |
|---|---|---|
| Full-context | OSS-20B | 39.0% |
| Zep | GPT-4o | 71.2% |
| Supermemory | GPT-4o | 81.6% |
| Hindsight | OSS-20B | 83.6% |
| Supermemory | GPT-5 | 84.6% |
| Hindsight | OSS-120B | 89.0% |
| Hindsight | Gemini-3 Pro | 91.4% |
README 里的 benchmark 图比纯数字更直观:
LoCoMo:
| 系统 | 总体准确率 |
|---|---|
| OpenAI Memory | 52.9% |
| Mem0 | 66.9% |
| Zep | 75.1% |
| Memobase | 75.8% |
| Hindsight (OSS-20B) | 83.2% |
| Hindsight (OSS-120B) | 85.7% |
| Hindsight (Gemini-3) | 89.6% |
几个值得注意的点:
-
架构 > 模型规模:Hindsight 用开源 20B 模型干到了 83.6%,超过了 Supermemory + GPT-4o(81.6%)。论文里明确说 "the memory architecture, rather than sheer model size, is carrying much of the performance"。
-
长程推理提升最大:multi-session(跨会话推理)从 21.1% 提升到 79.7%,temporal reasoning 从 31.6% 提升到 79.7%。这说明四路检索+时间感知的设计确实解决了 RAG 的痛点。
-
被独立复现:Virginia Tech Sanghani Center 和 The Washington Post 都独立复现了结果,不是自嗨。
但是,2026 年的竞争格局在快速变化:
- BYTEROVER(2026 年 4 月论文):LongMemEval-S 92.8%,LoCoMo 96.1%
- MemPalace:声称 LongMemEval 96.6%(raw),100%(hybrid with Claude Haiku reranking)
- Mastra Observational Memory:LongMemEval 94.87%,且不需要向量数据库
Hindsight 在 2025 年 12 月论文发布时确实是 SOTA,但现在已不是绝对领先。不过它有一个优势是工程成熟度:MIT 开源、有 Cloud 服务、有完整 SDK、Fortune 500 在生产环境使用。论文作者也来自 The Washington Post 和 Virginia Tech,学术背书足够。
七、适合谁,不适合谁
Hindsight 官方文档说得很诚实:
"Hindsight can be used with simple AI workflows like those built with n8n and other similar tools, but may be overkill for such applications."
我的判断:
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 个性化客服/AI 伴侣 | ✅ 非常适合 | Per-user memory 是最简单的 use case |
| AI Employee(自动化任务) | ✅ 核心场景 | open-ended tasks + 反馈学习 |
| Sales/Support Agent | ✅ 推荐 | Reflect 能帮 Agent 总结策略差异 |
| 简单的 n8n workflow | ❌ 没必要 | 标准 RAG 足够,Hindsight 太重 |
| 实时性要求极高的场景 | ⚠️ 需谨慎 | 四路检索+rerank 有额外延迟 |
还有一个实际问题:Hindsight 的 Retain 操作依赖 LLM 做抽取和归一化,这意味着每次 retain 都有 LLM 调用成本。如果你的 Agent 每轮对话要 retain 很多次,token 消耗会是个需要考虑的因素。论文里没有公开具体的延迟和成本数据,这是我目前最想看到的缺失信息。
八、总结
Hindsight 给我最大的启发不是它的 benchmark 分数,而是它对 Agent Memory 的重新定义:
记忆不应该只是外挂存储,而应该是 Agent 认知能力的一部分。
Retain/Recall/Reflect 三层操作的设计,World/Experiences/Mental Models 的架构分层,都是在朝这个方向走。它让 Agent 不只是"记得你说过什么",而是能"从你的反馈里学到应该怎么跟你合作"。
如果你现在正在给 Agent 加记忆,可以先问自己一个问题:
你的 Agent 记住了历史对话,但下一次遇到类似情况时,它的行为会因此改变吗?
如果答案是不会,那你的记忆系统可能只做到了 RAG 的级别。Hindsight 的价值,在于它给出了一个从"记住"到"学习"的工程路径。
至于要不要现在接入,我的立场很明确:
Hindsight 不是在所有场景都最优,但它定义了一个正确的方向:记忆必须是 Agent 认知的一部分,而不是外挂硬盘。 如果你现在给 Agent 加的记忆只是"把历史对话塞进向量库",那你的 Agent 记住了,但没学会。
如果你认同这个方向——无论最后选不选 Hindsight——它的 API 设计和仿生记忆架构都值得你花一个下午读一遍。
参考文献
[1] Latimer et al., Building Agent Memory that Retains, Recalls, and Reflects, arXiv:2512.12818, 2025 — https://arxiv.org/abs/2512.12818
[2] Hindsight Documentation — https://hindsight.vectorize.io
[3] Hindsight GitHub — https://github.com/vectorize-io/hindsight
[4] Wu et al., LongMemEval: Benchmarking Chat Assistants on Long-term Interactive Memory, ICLR 2025 — https://arxiv.org/abs/2410.10813
[5] Maharana et al., LoCoMo: Long Context Modeling for Multi-session Conversational AI, 2024
[6] BYTEROVER: Structured Context Trees for Long-Horizon Conversational Memory, arXiv:2604.01599, 2026
[7] MemPalace Benchmark Results — https://gamgee.ai/blogs/mempalace-verbatim-memory-benchmark/
本文链接:Hindsight 深度解析:为什么 Agent 有记忆,但还是不会学习? - https://h89.cn/archives/598.html
版权声明:原创文章 遵循 CC 4.0 BY-SA 版权协议,转载请附上原文链接和本声明。